231217第三次更新,更新完全覆盖之前的内容,查询可以GitHub历史记录
(25/03/01优化部分叙述)
单纯个人复习输出,很多图片参考MOOC浙江大学数据结构的课件
同时参考任课老师吕建明的课件内容
由于是个人输出,基于对生疏概念复习的需求,只是有选择性的做记录,很多内容都没有包含,仅供参考。
如果有出错或者疑问的,我愿意一同探究解惑。按道理能看到这篇博客就有我的联系方式。没有就发邮件。考虑到可能承担未妥善管控不当言论的风险,暂不考虑开评论区/留言板。
一、时间复杂度
1.时间复杂度的符号(上界下界确界)
参考文章:https://blog.csdn.net/anshuai_aw1/article/details/108449000
2.常见操作时间复杂度:
参考http://t.csdnimg.cn/oAog6
链表、堆栈、队列:插入删除O(1);查找O(n)
二叉搜索树:都是O(logN)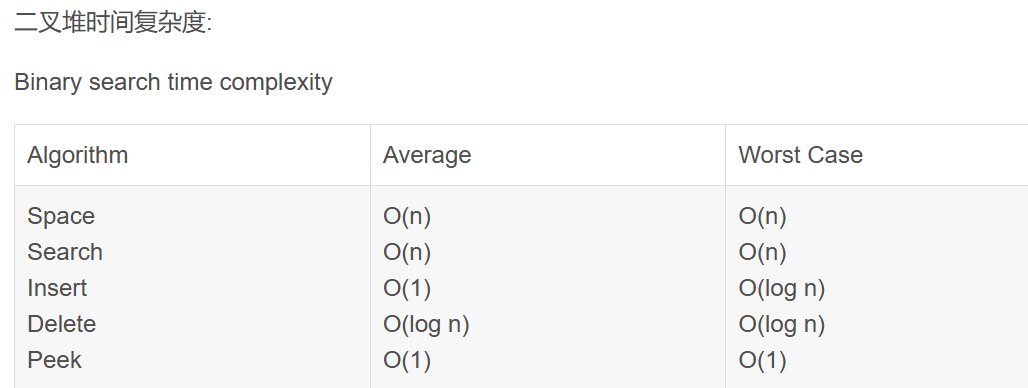

二、链表
1.fence:课件中的定义:”The position of a list to execute operations is defined as a fence.”栅栏体现的是当前操作的位置。不同操作对应位置会有区别,结合下图更好理解。
三、树
- 树的深度与高度
教材定义:结点的深度是从根到结点的距离(The depth of a node M in the tree is the length of the path from the root of the tree to M),高度比最大深度大一;
设总层数为n,则height=n; depth_max=n-1。
网上查阅时,有些教材定义根所在层数为1的,但按用的教材定义是根所在层数是0,导致最大深度是n-1,高度不受影响还是n。(顺带一提,2-3树也一样,注意根的深度是0) - 满(full)二叉树与完全(complete)二叉树
full binary tree,满二叉树要求每层都达到最大结点树,即结点个数是2^n-1;
complete binary tree,完全二叉树要求最后一层的结点必须从左到右连续,尤其以数组存储时最大结点下标为n,则n以前的有效下标都得有数据
(至于下标为0的就看怎么构建了,注意一下在堆中0有没有放哨兵,0不存有效数据是父子下标对应关系会变的,不过课上讲的好像没用哨兵;哨兵放比数据范围更大或更小的值,比较时哨兵就可以起到防止越界的作用) - 注:普通树考点有集合union
- 遍历一棵二叉树方法:前序(PreOrder)、中序(InOrder)、后序(PastOrder)还有层序(LevelOrder)。
前中后序三种遍历方式都是以根节点相对于它的左右孩子的访问顺序定义的。例如根->左->右便是前序遍历,左->根->右便是中序遍历,左->右->根便是后序遍历,层序遍历是一层一层来遍历。
四、图
1.最短路径问题:
单源最短路径:从某固定源点出发,求其到所有其它顶点的最短路径
多源最短路径:求任意两顶点间的最短路径
有权图的单源最短路算法:Dijkstra算法
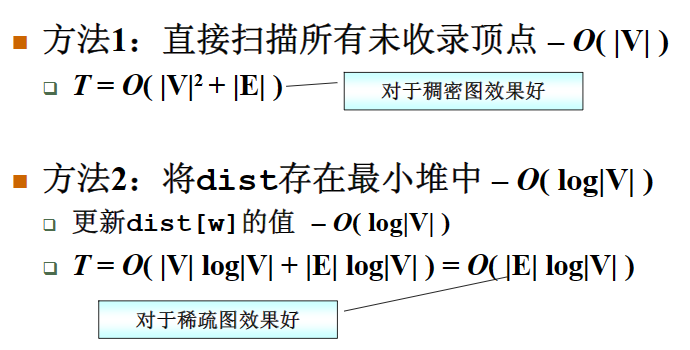
(多源最短路算法:Floyd算法,教材上没有,思想差不多)

2.最小生成树问题
(1)Prim算法:贪心法,每次取与邻接点间的边中的最短边
(2)Kruskal算法:将森林合并成树,每次取所有边中的最短边,如果不构成回路就加入。(用并查集,跟集合差不多。根结点存放-n,n表示所在集合中的元素个数;非根元素存放父亲结点,即父亲结点的下标)
五、散列/哈希
1.open hashing,简单来说,指针存储,无限空间。别的都是closed hashing,只能在有限的哈希表里。
2.冲突处理Collision Resolution Methods
下面的都属于探测散列表(probing hash table),与之相对的另一类方法是分离链接法(separate chaining),就是存指针弄链表。
线性侦测法(Linear Probing)向后逐个试探,主要还是看它给的p(K,i)是什么,一般是用h(K)+p(K,i)作为下标检测是否为空/命中。
对于平方探测法(quadratic probing),课本里给的形式是通用的,可以理解为p(K,i)是二次函数,课本原话p(K,i)=i^2是最简单平方探测法的例子。考的话应该会给p(K,i)的。(写代码用的话我是用正负i^2的)
(什么时候可能正负都要试,见下图:源自浙江大学MOOC数据结构的讲义)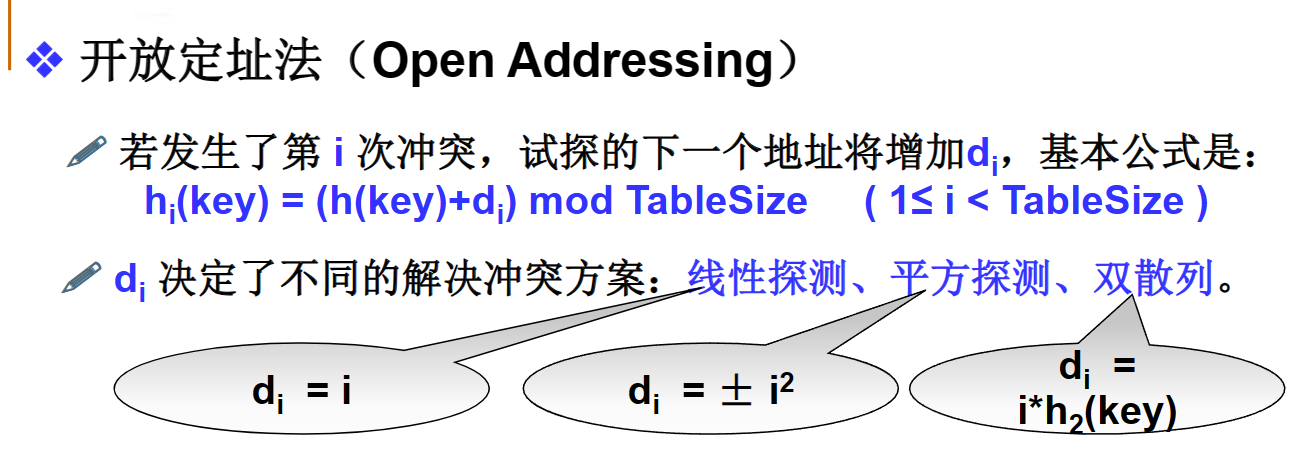
(使用平方探测仍会产生二次聚集(secondary clustering),大致就是h(x)一致,为解决这个缺憾引出了双散列(double hashing))
3.注:删除时要设墓碑。(但对散列要求没这么高吧,不过掌握没坏事)
六、索引
1.2-3树
具体操作可以参考下面这篇文章
https://blog.csdn.net/kexuanxiu1163/article/details/87887529
2.B-树与B+树(区分:B+分别索引结点和叶子结点,所有数据都保存在叶子结点中)
https://blog.csdn.net/u014453898/article/details/112469113
七、排序
(基本术语:内部排序Internal Sorting 给内存里的排序、外部排序External Sorting 给磁盘里的排序)
1.简单排序
冒泡排序、插入排序都稳定;选择排序不稳定
选择排序可以优化为堆排序(O(nlogn)),快速找到最小值。
2.Shellsort希尔排序

(有归并排序mergesort这个东西,二分法思想)
3.快速排序QuickSort
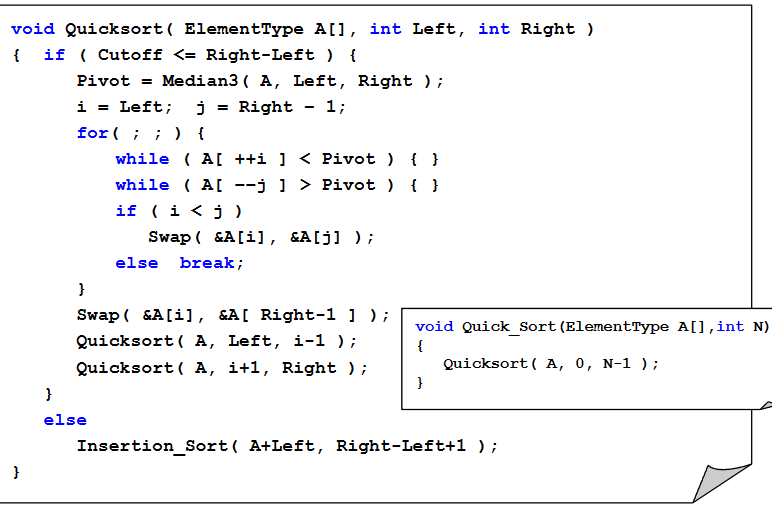
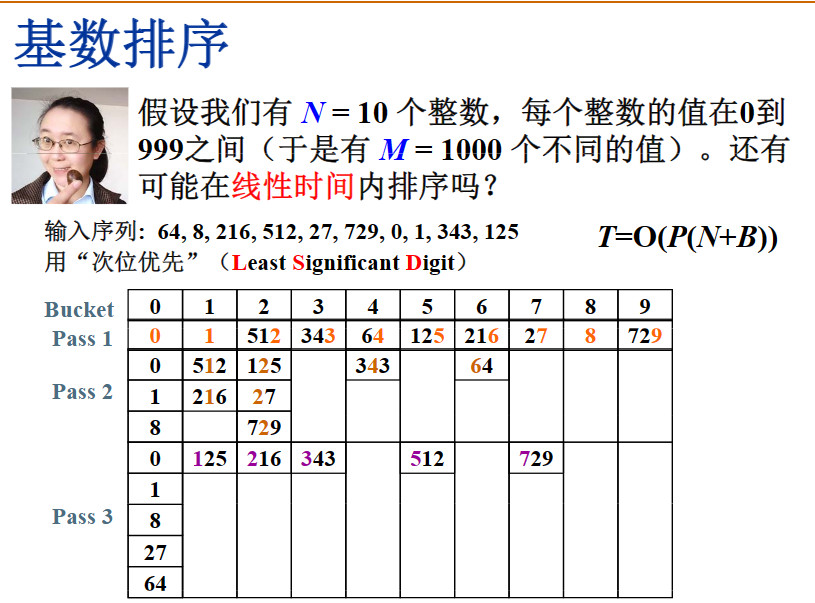
4.箱/桶排序BinSort:很像哈希(散列)的开放定址法,都是空间换时间,T(N,M)=O(M+N)
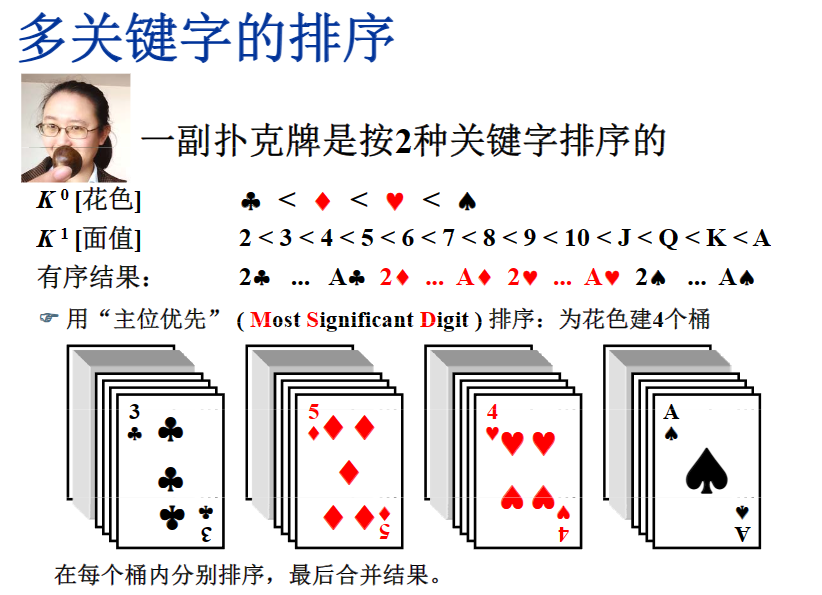
5.基排序RadixSort,次位优先主位优先