前言: 在个人在学校中接触的项目当中,接触到翻译相关的功能需求。为了取得可叠加的进步,我会将过程逐步记录(粒度粗细不定),并在重新整理成博客文章的过程中补充原理细节,重塑结构。需要注意:内容的先后顺序并非思想的先后顺序,是按归纳总结时的思路行文的。
目标:
学习PDFMathTranslate项目调用modelscope模型完成翻译的代码;
在1的基础上,学习书写出modelscope翻译模块
正文 目标1:学习PDFMathTranslate项目调用modelscope模型完成翻译的代码。
在接触的优秀代码不足、相关功能经验有限的情况下,我还是偏向阅读已有的优秀项目进行学习。针对这一小目标,我的具体操作是从相关功能代码中提取独立的模块。
(一)PDFMathTranslate项目中的Google翻译功能 代码阅读与原理解析(Google翻译) 简单概括:这段代码通过requests.Session()模拟浏览器 请求,以访问谷歌翻译的移动端网页接口 ,并从谷歌翻译网站返回的HTML响应 中提取翻译结果。
requests.Session()的用法requests.Session()中的get方法。尽管如此,我们还是得要理解为什么要使用requests.Session(),了解一下requests.Session()的特性。
首先,Session 对象能够自动在多个请求之间保持连接 ,这叫作连接复用。相比于每次调用 requests.get() 都新建一次 TCP 连接,使用 Session 可以显著提高网络请求的性能,尤其是在需要频繁访问同一个服务器的情况下,例如多个段落翻译、批量文本处理等场景中。
我们可以通过下面这个脚本的输出结果,直观地对比采用连接复用前后的性能差别。
import requestsimport timeurl = "https://httpbin.org/get" start = time.time() for _ in range (5 ): requests.get(url) print ("不使用 Session 耗时:" , time.time() - start)session = requests.Session() start = time.time() for _ in range (5 ): session.get(url) print ("使用 Session 耗时:" , time.time() - start)
输出:
不使用 Session 耗时: 11.803440809249878 使用 Session 耗时: 3.7048346996307373
其次,Session 会在内部自动维护 Cookies ,这使得我们可以模拟真实用户的行为。例如,如果谷歌翻译网站设置了某些认证 Cookie 或使用了一些跳转机制,只要在第一次请求中设置好了,后续请求就会自动携带这些 Cookie 而不需要手动干预。这对于避免被服务器识别为机器人或提高请求成功率是非常有帮助的。
另外,Session 还允许我们设置全局的请求头(headers)和代理(proxies) ,在本代码中就用到了 User-Agent 头部,它模拟了一个旧版浏览器的身份。这种设置在 Session 中只需定义一次,后续所有请求都会自动继承,大大简化了代码结构。
import requestssession = requests.Session() session.get("https://httpbin.org/cookies/set/sessioncookie/123456" ) session.headers.update({ "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" }) from requests.adapters import HTTPAdapterfrom urllib3.util.retry import Retryretries = Retry(total=3 , backoff_factor=0.5 , status_forcelist=[500 , 502 , 503 , 504 ]) adapter = HTTPAdapter(max_retries=retries) session.mount("http://" , adapter) session.mount("https://" , adapter) response = session.get("https://httpbin.org/status/500" )
这段代码只是给出了设置相关字段的示例。执行后,由于api会返回500错误,最终会导致如下输出:
"name": "RetryError", "message": "HTTPSConnectionPool(host='httpbin.org', port=443): Max retries exceeded with url: /status/500 (Caused by ResponseError('too many 500 error responses'))", ......
get方法————HTTP请求格式get请求方法的输入是这段代码的关键一环。如果没有网络开发基础,建议自行搜索学习。本文不展开说明。
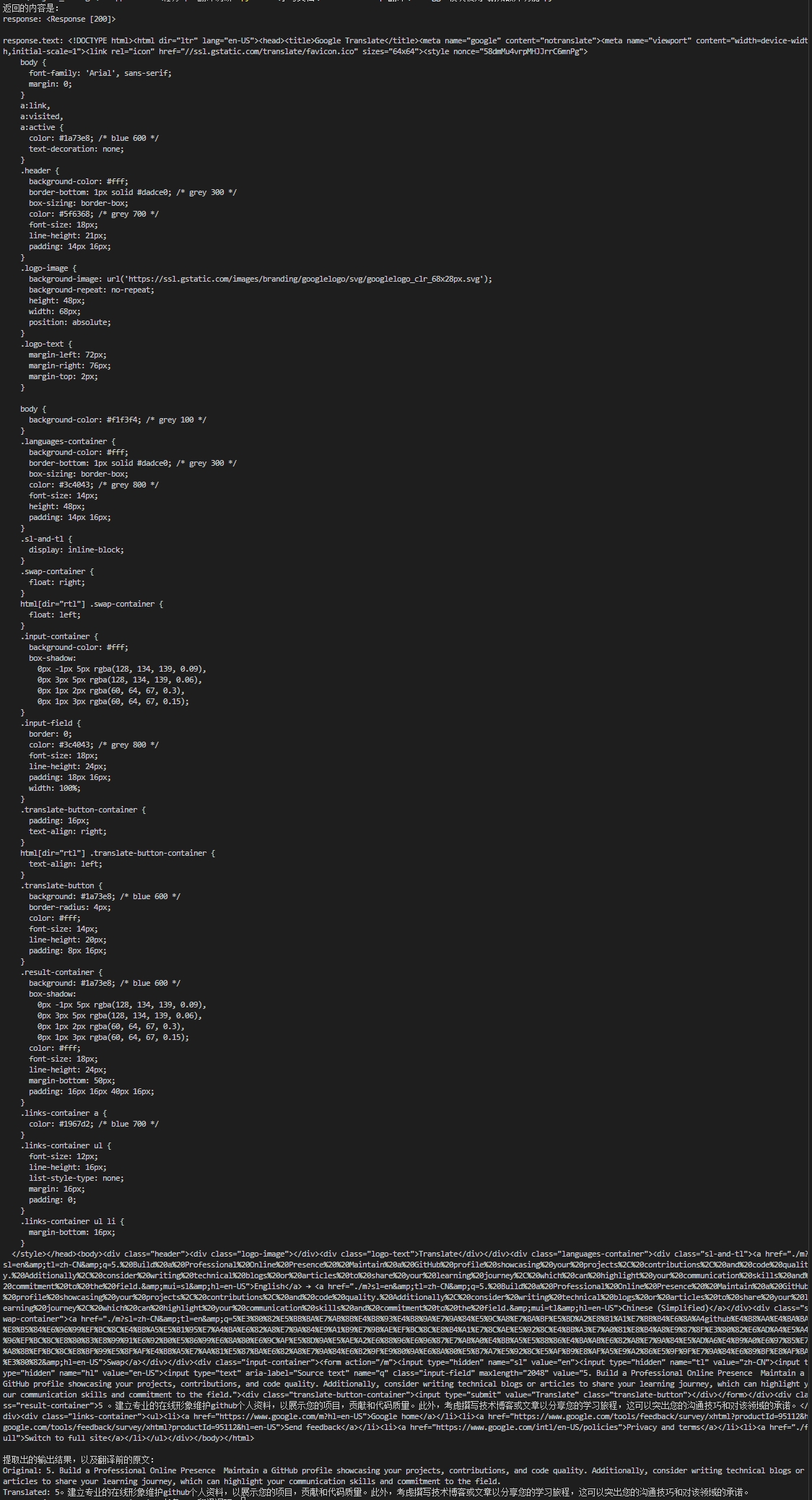
从Google翻译网页的返回内容提取翻译结果
当我们使用 requests 访问 Google 翻译网页时,Google 实际返回的是一个 移动版网页的 HTML 页面 。我们需要从这个 HTML 中提取翻译结果文本 ,而不是像使用 API 那样直接得到一个结构化的 JSON 响应。为了便于理解,我将结合具体的输出进行说明:
返回内容是一个HTML,如果没有了解过HTML页面的读者可以自行了解一下。在<head></head>标签内是页面样式,在body部分,<input>内是我们的输入,<div class="result-container">的<div></div>标签中是翻译结果。
明确了翻译结果所在的结构,接下来我们就要从返回的HTML中提取我们需要的翻译结果:
在 Python 中,我们使用 re.findall() 结合正则表达式快速提取:
import rehtml_text = ''' <div class="result-container">你好,世界!这是一个测试翻译。</div> ''' result = re.findall(r'(?s)class="(?:t0|result-container)">(.*?)<' , html_text) print (result[0 ])
解释:这个正则表达式会寻找 class="t0" 或 class="result-container" 的 <div> 元素,并提取它里面的文本。
Google 的 HTML 返回中有时使用 "t0",有时用 "result-container",所以我们用 (?:t0|result-container) 来同时匹配这两种情况。
对翻译结果的额外处理
在返回的HTML网页中中,有一些特殊字符(如 &, <, > 等)具有特殊含义,所以必须用“HTML 实体”来编码。
不过,在处理这些特殊字符前,不妨了解一下:“为什么会有这些特殊字符?”
4.1 为什么会有 HTML 实体?
在 HTML 中:
实体编码
表示字符
用途
&&避免与 HTML 中 & 开头的实体冲突
<<避免被误解为标签的开始符号
>>避免被误解为标签的结束符号
""表示引号
''表示单引号
所以,如果你翻译的原文或结果中包含这些字符,为了在 HTML 页面中显示正确,就会用这些实体代替真实字符。
4.2 为什么会有控制字符?
控制字符是指那些看不到,但有特殊功能 的字符,比如:
字符
Unicode 类别
功能示例
\nCc (控制字符)
换行符
\rCc
回车符
\tCc
制表符
\x0cCc
换页符
网页抓取过程中,这些控制字符可能会:
被翻译引擎带进来(尤其是复制粘贴的源文本中含有这些字符)
出现在网页返回的隐藏结构中
它们在机器阅读中没影响,但会导致输出不干净、在某些终端下显示异常。
为了获得干净、真实、可用的翻译文本,我们必须:
用 html.unescape() 处理 HTML 实体
用 unicodedata.category(ch) 判断字符是否属于控制字符(类别以 C 开头),然后去除
4.3 具体处理
对于 & 表示 &,< 表示 <的这类情况,我们用 html.unescape() 转换它们为真实字符:
import htmltext = "This & that" cleaned = html.unescape(text) print (cleaned)
对不可见的控制字符(如换页符、不可打印字符等),我们用 unicodedata 模块进行清除:
import unicodedatadef remove_control_characters (s ): return '' .join(ch for ch in s if unicodedata.category(ch)[0 ] != "C" )
使用主要功能代码写出的demo(Google翻译) import unicodedataimport htmlimport reimport requestsdef remove_control_characters (s ): return "" .join(ch for ch in s if unicodedata.category(ch)[0 ] != "C" ) class BaseTranslator : name = "base" lang_map: dict [str , str ] = {} def __init__ (self, lang_in: str , lang_out: str , model: str ): lang_in = self.lang_map.get(lang_in.lower(), lang_in) lang_out = self.lang_map.get(lang_out.lower(), lang_out) self.lang_in = lang_in self.lang_out = lang_out self.model = model def translate (self, text: str ) -> str : return self.do_translate(text) def do_translate (self, text: str ) -> str : raise NotImplementedError class GoogleTranslator (BaseTranslator ): name = "google" lang_map = {"zh" : "zh-CN" } def __init__ (self, lang_in, lang_out, model="default" ): super ().__init__(lang_in, lang_out, model) self.session = requests.Session() self.endpoint = "https://translate.google.com/m" self.headers = { "User-Agent" : "Mozilla/4.0 (compatible;MSIE 6.0;Windows NT 5.1;SV1;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.30)" } def do_translate (self, text ): text = text[:5000 ] response = self.session.get( self.endpoint, params={"tl" : self.lang_out, "sl" : self.lang_in, "q" : text}, headers=self.headers, ) re_result = re.findall(r'(?s)class="(?:t0|result-container)">(.*?)<' , response.text) if response.status_code == 400 : result = "TRANSLATION ERROR" else : response.raise_for_status() result = html.unescape(re_result[0 ]) return remove_control_characters(result) def main (): translator = GoogleTranslator(lang_in="en" , lang_out="zh" ) text_to_translate = "Hello, world! This is a test translation." translated_text = translator.translate(text_to_translate) print (f"Original: {text_to_translate} " ) print (f"Translated: {translated_text} " ) if __name__ == "__main__" : main()
(二) PDFMathTranslate项目中借助ModelscopeAPI进行翻译 代码阅读与原理解析(ModelScopeAPI) ModelScopeAPI是一个调用大语言模型的接口,不像是Google翻译是一个在线网页。我们实际上是在调用模型,让模型让我们完成翻译的工作。为此,我们需要调用模型,通过给模型prompt(提示词)来获取我们期待的回复。
ModelScope的请求头需要包含API_KEY的信息,需要在请求体中指明使用的模型。可以结合下面这段具体的代码进行理解。(下面这段代码是截取的内容,无法独立运行!)
self.session = requests.Session() self.session.headers.update({ "Authorization" : f"Bearer {self.api_key} " , "Content-Type" : "application/json" }) def do_translate (self, text: str ) -> str : messages = self.prompt(text, self.prompt_template) body = { "model" : self.model, "messages" : messages } response = self.session.post(f"{self.base_url} /chat/completions" , json=body) response.raise_for_status() content = response.json()["choices" ][0 ]["message" ]["content" ] return remove_control_characters(content.strip())
先前我的博客(两篇都是step by step的大模型微调)中,应该有进行过“提取模型输出”的处理。但为了便于直观地理解,这里还是贴出response的打印结果。
至于如何从json结构中提取我们需要的字段,不理解原理的读者可以问一下大模型。本文将其当作大家都会的基本概念了。
使用主要功能代码写出的demo(ModelScopeAPI) import osimport reimport requestsimport unicodedatafrom string import Templatefrom typing import castdef remove_control_characters (s ): return "" .join(ch for ch in s if unicodedata.category(ch)[0 ] != "C" ) class BaseTranslator : name = "base" envs = {} lang_map: dict [str , str ] = {} CustomPrompt = False def __init__ (self, lang_in: str , lang_out: str , model: str , ignore_cache: bool = False ): lang_in = self.lang_map.get(lang_in.lower(), lang_in) lang_out = self.lang_map.get(lang_out.lower(), lang_out) self.lang_in = lang_in self.lang_out = lang_out self.model = model self.ignore_cache = ignore_cache def set_envs (self, envs ): self.envs = self.__class__.envs.copy() if envs is not None : self.envs.update(envs) def translate (self, text: str , ignore_cache: bool = False ) -> str : return self.do_translate(text) def prompt (self, text: str , prompt_template: Template | None = None ) -> list [dict [str , str ]]: try : return [ { "role" : "user" , "content" : cast(Template, prompt_template).safe_substitute( { "lang_in" : self.lang_in, "lang_out" : self.lang_out, "text" : text, } ), } ] except Exception: pass return [ { "role" : "user" , "content" : ( "You are a professional, authentic machine translation engine. " "Only Output the translated text, do not include any other text.\n\n" f"Translate the following markdown source text to {self.lang_out} . " "Keep the formula notation {{v*}} unchanged. " "Output translation directly without any additional text.\n\n" f"Source Text: {text} \n\nTranslated Text:" ), } ] class ModelScopeTranslator (BaseTranslator ): name = "modelscope" envs = { "MODELSCOPE_BASE_URL" : "https://api-inference.modelscope.cn/v1" , "MODELSCOPE_API_KEY" : None , "MODELSCOPE_MODEL" : "Qwen/Qwen2.5-7B-Instruct" , } def __init__ ( self, lang_in: str , lang_out: str , model: str = None , base_url: str = None , api_key: str = None , envs: dict = None , prompt: Template = None , ignore_cache: bool = False , ): super ().__init__(lang_in, lang_out, model, ignore_cache) self.set_envs(envs) self.base_url = base_url or self.envs["MODELSCOPE_BASE_URL" ] self.api_key = api_key or self.envs["MODELSCOPE_API_KEY" ] self.model = model or self.envs["MODELSCOPE_MODEL" ] self.prompt_template = prompt self.session = requests.Session() self.session.headers.update({ "Authorization" : f"Bearer {self.api_key} " , "Content-Type" : "application/json" }) def do_translate (self, text: str ) -> str : messages = self.prompt(text, self.prompt_template) body = { "model" : self.model, "messages" : messages } response = self.session.post(f"{self.base_url} /chat/completions" , json=body) response.raise_for_status() content = response.json()["choices" ][0 ]["message" ]["content" ] return remove_control_characters(content.strip()) def main (): MODELSCOPE_API_KEY = os.environ.get("MODELSCOPE_API_KEY" ) or "YOUR_MODELSCOPE_API_KEY" translator = ModelScopeTranslator( lang_in="en" , lang_out="zh" , api_key=MODELSCOPE_API_KEY ) input_text = "This is a test of the ModelScope translator with prompt formatting." output = translator.translate(input_text) print (f"原文:{input_text} " ) print (f"译文:{output} " ) if __name__ == "__main__" : main()